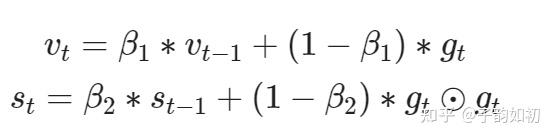在深度学习任务中,我们常常会为模型定义一个损失函数,损失函数表征的是预测值和实际值之间的差距,再通过一定的优化算法减小这个差距
然后绝大多数情况下,我们的损失函数十分复杂,不像我们解数学题能得到一个确定,唯一的解析解。而是通过数学的方法去逼近一个解,也称数值解
当该函数有两个波谷,分别是局部最小值和全局最小值。
到达局部最小值的时候,由损失函数求得的梯度接近于 0,我们很难再跳出这个局部最小值,进而优化到全局最小值,即 x=1 处,这也是损失函数其中的挑战。
因此当学习率很小,我们下降较为平滑,但容易卡在局部最小值点
当学习率很大,我们梯度优化过程中会十分剧烈,可能达到全局最小值点,但也很可能距离优化目标越来越远
假设我们有 n 个样本数据,那么每次进行梯度下降,我们需要分别对每个数据计算其梯度。
时间复杂度为 O(n),当样本很多的时候,这个计算开销是非常大的。
随机梯度下降则是在梯度下降每次迭代当中,随机采取一个样本,计算其梯度,作为整体梯度进行下降,我们的计算开销也就下降到了 O(1)
为了梯度值更稳定,我们也可以选择小批量随机梯度下降,以一小批样本的梯度作为整体的梯度估计
由于loss函数大多都是多维的情况,常常会出现下面两个问题,大大影响了模型收敛
- 当函数在某个方向上变化十分剧烈,则对应方向上的梯度变化也十分剧烈。
- 目前SGD只是单一得考虑了当前的梯度,而忽略了以前的梯度情况。
因此Momentum应声而出,需要把以前的梯度也加入到当前梯度计算中,加速收敛(参考移动指数平均)
因此新增了一个速度变量,初始化为 0,由以下两个公式进行变量维护
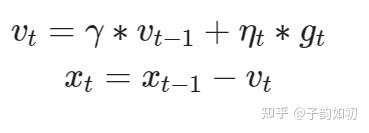
用于BN中测试使用的std和mean拟合计算,beta 一般选取0.9,0.98, 0.99, 0.999等。越小,过去累计值的权重越低,当前抽样值的权重越高,移动平均值的实时性就越强。反之
越大,吸收瞬时突发值的能力变强,平稳性更好。(对于时间)

之前的算法中都是使用同一学习率来自我迭代。
但是不同学习率所带来的优化效果也不同,因此能否提出一个自适应学习率调整的优化算法
AdaGrad即如此,通过添加一个状态变量s,e是个很小的数防除以0,使每个变量就有自己特定的学习率,而且状态变量放置在分母下,能逐步调小学习率, 不需要人为进行调整。缺点就是可能模型还未收敛,学习率已经过小

AdaGrad 缺点是因为平方函数是个递增函数,一直迭代会让学习率持续下降。而移动平均不是一个单调的函数
因此 RMSProp 算是结合了 Adagrad 和 动量法的移动平均思想,用于更新状态变量 s
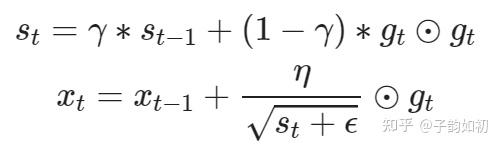
Adam是目前所有优化器中的集大成者,在使用预训练模型时经常使用学习率较小的adam