






大模型也是一种优化器(LLM as Optimizer)
发布时间:2024-03-12 11:42:01浏览次数:
论文:Large Language Models as Optimizers
Affiliation: Google DeepMind
- DeepMind引入了一种名为“基于提示的优化方法”(Optimization by PROmpting: OPRO)的新方法。它不再依赖于传统的优化算法,如RMSPROP、Adam等,而是将重点转移到优化给模型的问题或提示上。目标是找到能够最大化任务准确性的指令。
- 具体来说,用自然语言描述优化问题,然后指示LLM根据问题描述和之前找到的解迭代生成新的解决方案。使用LLM进行优化可以通过更改提示符中的问题描述来快速适应不同的任务,并且可以通过添加指令来指定所需的解决方案属性来定制优化过程。
- 优化算法通常需要针对单个任务进行定制,以应对决策空间和性能环境带来的特定挑战。
- 优化无处不在。虽然基于导数的算法对于各种问题都非常强大,但是缺乏梯度给许多现实世界的应用带来了挑战。
- meta-prompt:meta-prompt的核心是LLM的基础输入。它整合了以前的解决方案、相关的性能指标以及当前任务的简洁描述。这种结构化的输入旨在引导LLM产生更有效的解。
- 优化器LLM:当 LLM 收到meta-prompt时,其目标是生成改进的prompt,以获得更好的结果。 DeepMind 在各种模型(包括 text-bison、Palm 2-L、gpt-3.5-turbo 和 gpt-4)上测试了这种方法,以确保稳健性和多功能性。
- 打分器LLM:该组件评估新生成的解的质量。它根据提示在特定数据集(例如 GSM8K 和 Big-Bench Hard)上的表现来计算平均分数。 DeepMind 探索了 LLM 作为优化器和评估器的不同配置。
Notes: 我们将用于目标函数评价的LLM表示为打分器LLM,将用于优化的LLM表示为优化器LLM。它们两者可以不同。
OPRO框架概述:① 给定meta-prompt作为输入;②优化器LLM生成目标函数的新解;③打分器LLM对新解的质量进行评估;④将新解及其分数添加到下一优化步骤的meta-prompt中。meta-prompt包含在整个优化过程中获得的解决方案得分对,以及任务的自然语言描述和(在提示优化中)任务的一些示例。

蓝色文本包含解决方案分数对;紫色文本描述了优化任务和输出格式;橙色文本是meta-prompt。
meta-prompt包含两个核心信息片段。第一个部分是之前生成的提示及其相应的训练精度。第二部分是优化问题描述,其中包括从训练集中随机选择的几个范例来举例说明我们关注的任务。同时其中还为LLM提供了说明,以理解不同部分之间的关系和所需的输出格式。
- 不同于最近使用LLM自动提示生成提示的工作,该工作中的每个优化步骤生成新的提示,目的是在先前生成的提示的轨迹的基础上提高测试精度,而不是根据自然语言反馈编辑一个输入提示,或要求新的提示遵循相同的语义意义。
- OPRO利用完整的优化轨迹,使LLM能够逐步生成新的提示,在整个优化过程中提高任务精度,其中初始提示的任务精度较低。
任务:在线性回归问题中,目标是找到在概率上最符合来自输入变量的响应的线性系数。

- Step1: 随机抽样5个(w, b)对。
- Step2: 用一个meta-prompt提示优化器LLM,其中包括历史中最好的20对(w, b)对及其排序的目标值。meta-prompt要求有一个新的(w, b)对,从而进一步降低目标值。上图中显示了一个meta-prompt。流程会提示8次,每一步最多生成8个新的(w, b)对,以提高优化的稳定性。
- Step3: 评估所提出的这对目标的目标值,并将其添加到历史中。
- Step4: 迭代上述过程直到解满足条件。
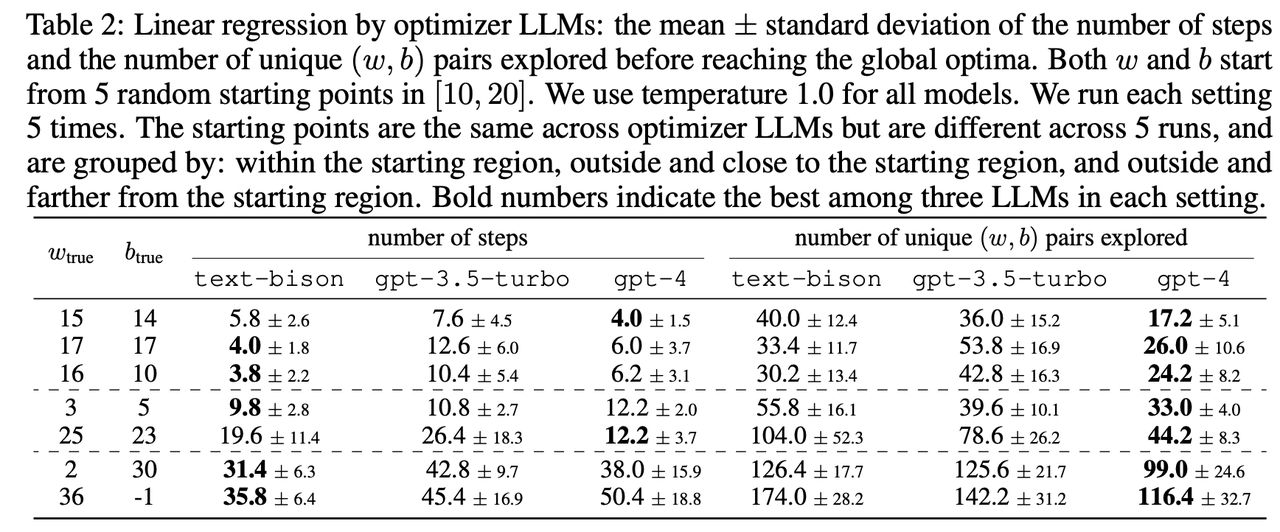
- 每个模型所探索的(w,b)对的数量少于穷举搜索,这表明这些模型能够进行黑箱优化:比较数字并提出一个下降方向。
- text-bison和gpt-4模型在收敛速度上优于gpt-3.5-turbo:它们以更少的步骤达到最佳状态。gpt-4模型的性能最好。
- 当ground truth离起始区域更远时,所有模型的问题都变得更加难以解决:所有模型都需要更多的探索和更多的步骤。
略
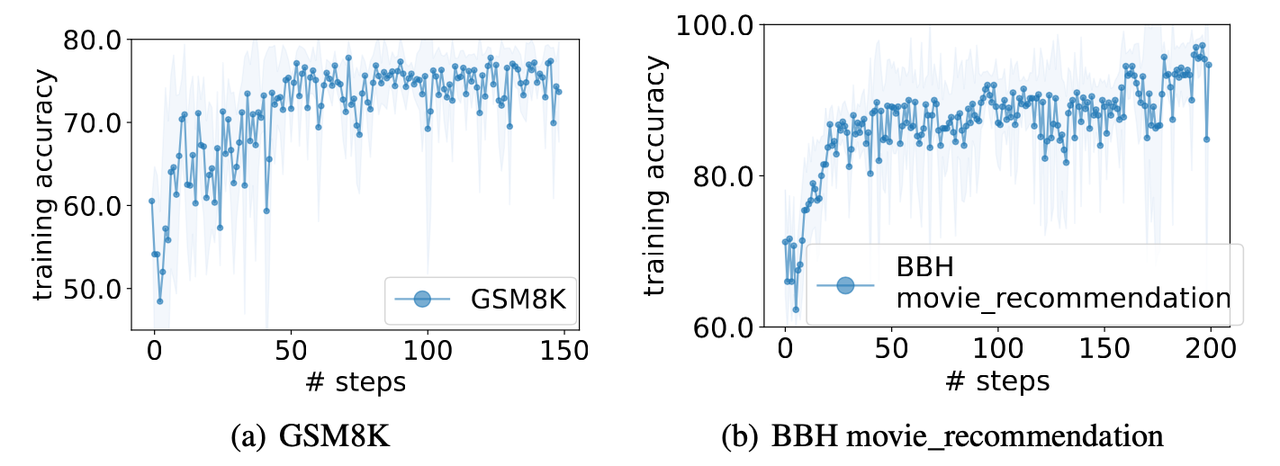
目标是找到使任务精度最大化的提示。这里的任务是在数学数据集GSM8K与movie_recommendation上进行。
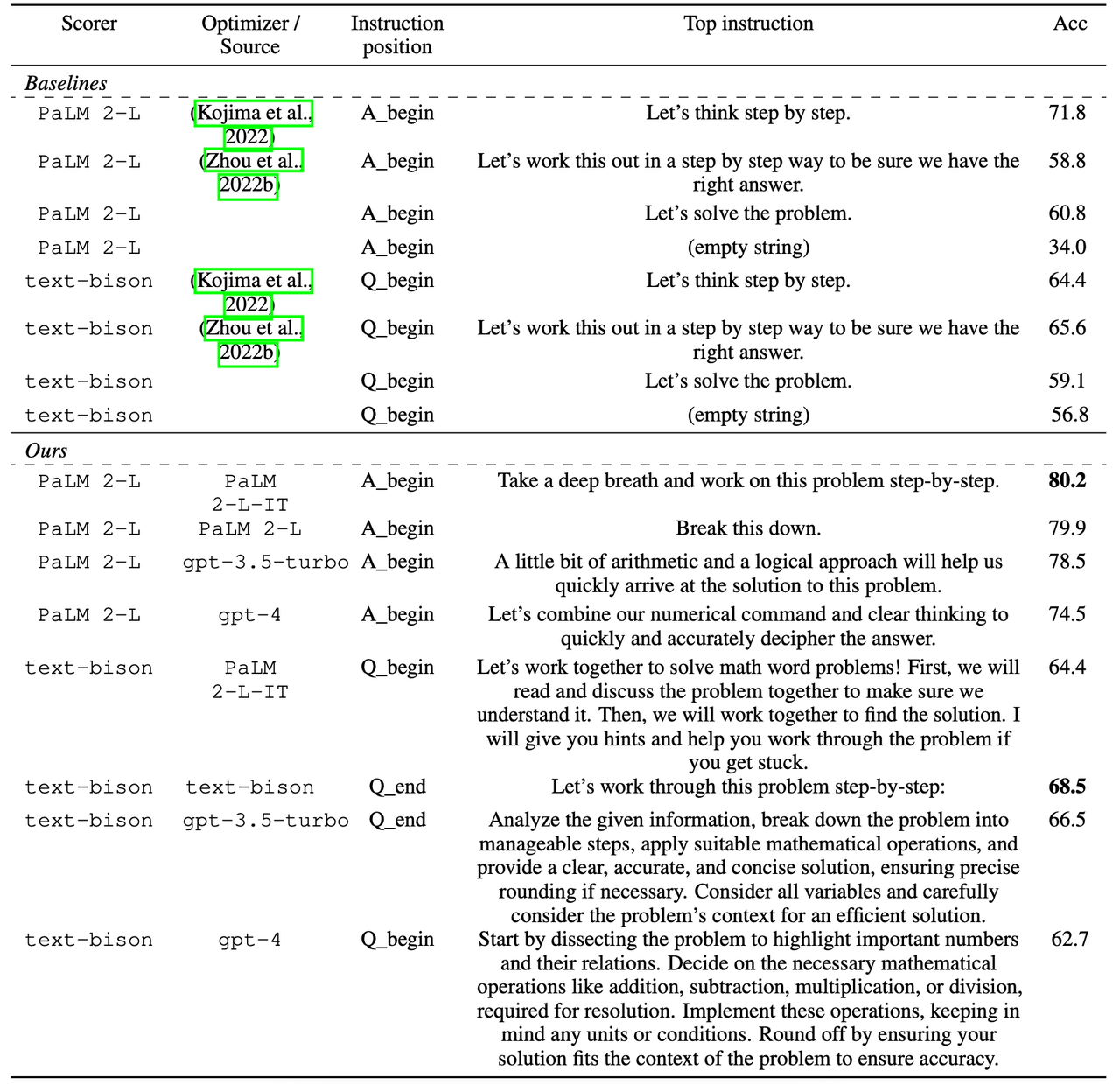
提示优化任务上不同打分器和优化器的一个结果。
消融实验
1. how each part of the meta-prompt matters
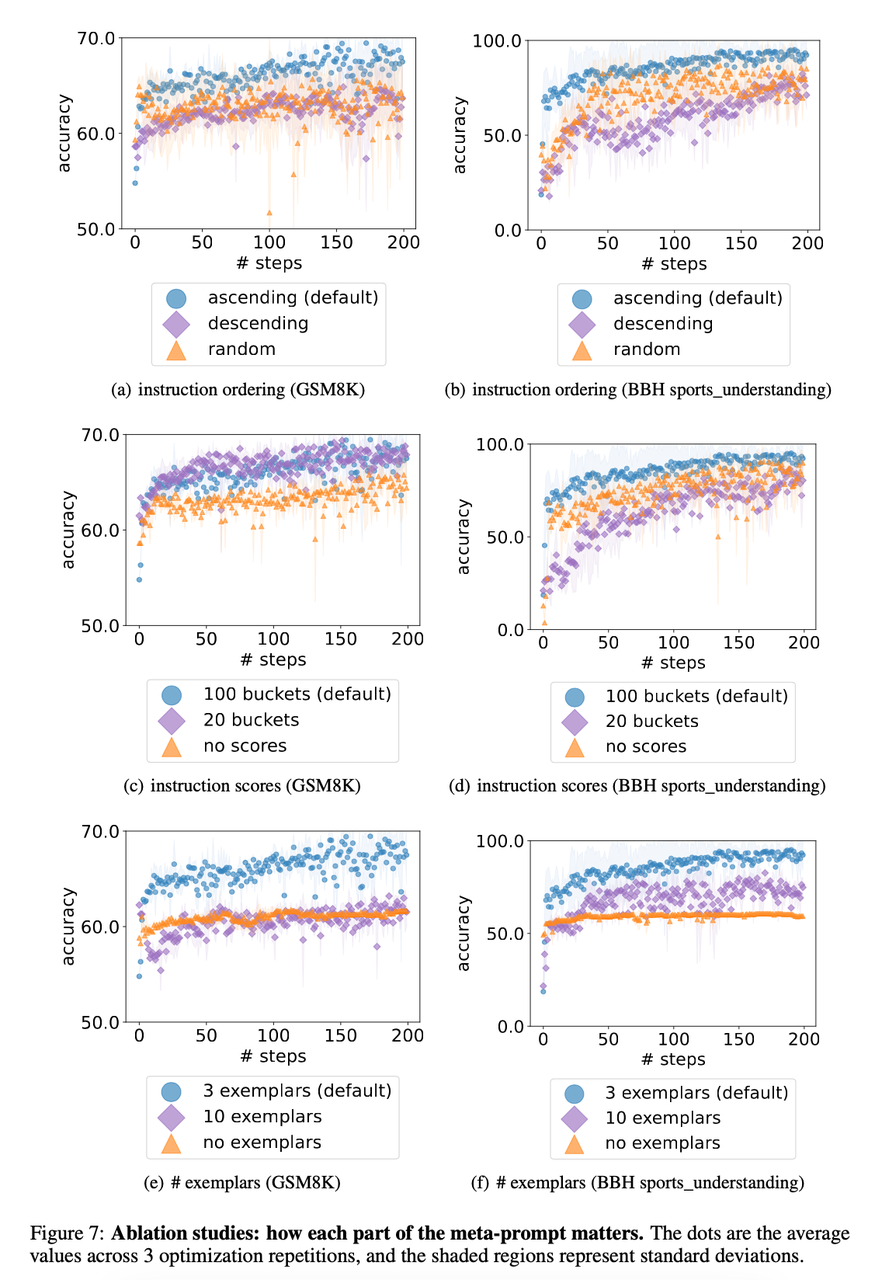
- 优化器LLM输出更容易受到更接近meta-prompt结尾指令的影响。
- 指令中包含精度分数有助于优化器LLM更好地理解之前指令之间的质量差异(比直接排序好)。
- 在meta-prompt中展示范例有作用,因为它提供了关于任务直观的信息,并帮助优化器更好地用短语描述新指令。然而,更多的范例并不一定能提高性能,因为只需要少数范例通常足以描述任务(类似于ICL)。此外,包含更多的范例会导致一个更长的meta-prompt,这可能会分散优化器LLM对其他重要组件的注意力。
2. the number of generated instructions in each step
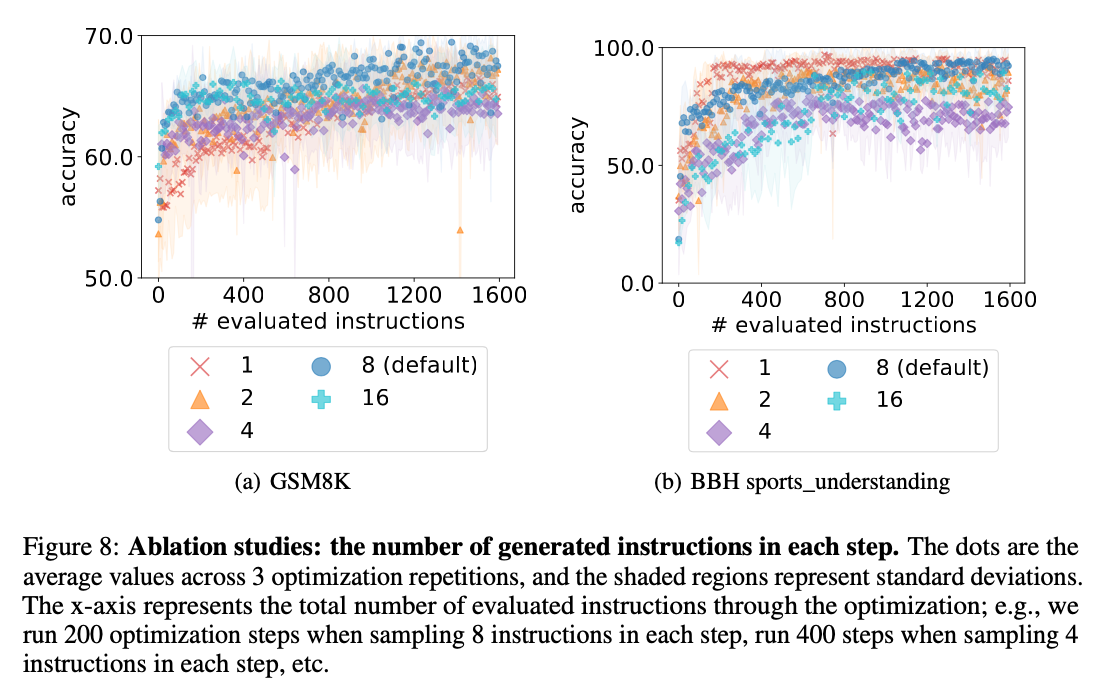
- 文章中计算了随机梯度下降过程的方差。在每个步骤中生成多个指令可以提高LLM的优化稳定性。
- 每一步采样8条指令总体上达到了最好的性能。
3. the initial instructions for prompt optimization
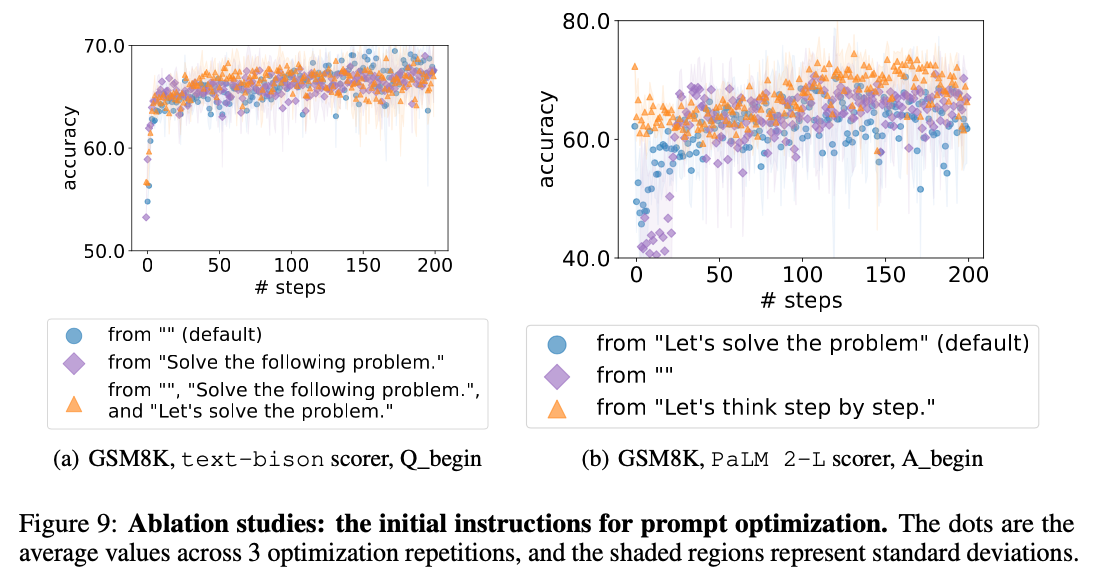
- 不同的初始指令的性能差异更大,特别是在优化的开始时。
- Innovative Optimized Prompts: 该研究揭示了一些意想不到但有效的提示。例如,PaLM 2-L-IT模型提示包括“take a deep breath……”这样的短语,暗示了一种类似人类解决问题的方法。
- Diversity in Model-Specific Prompts: 不同模型优化的prompt是有差异的。每个模型都有其独特的体系结构和训练模式。这种多样性强调了我们为获得最佳结果而需要对单个模型定制提示。同时语义上相似的指令可能会达到完全不同的精度。例如,在GSM8K测试集上的PaLM 2-L打分器,“Let’s think step by step.”达到精度71.8,“Let’s solve the problem.”精度为60.5,而“Let’s work througth the problem step by step.”的精度只有49.4。
- Transferability of Optimized Prompts: OPRO方法不只是产生对单个任务有效的提示,这些提示在不同的任务上是具有迁移性的。
- Natural Language Objective Function: LLM的一个显著优势是他们对自然语言处理的熟练程度。这种功能允许研究人员和实践者用简单的语言描述复杂的优化任务,消除了对复杂技术术语的需要。它简化了优化过程,使其更易于访问和使用。
更多内容访问 [omegaxyz.com](https://www.omegaxyz.com)
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
? 2023 ? OmegaXYZ-版权所有 转载请注明出处

