






- 随机梯度下降法(SGD)
如果我们的样本非常大,比如数百万到数亿,那么计算量异常巨大。因此,实用的算法是SGD算法。在SGD算法中,每次更新的迭代,只计算一个样本。这样对于一个具有数百万样本的训练数据,完成一次遍历就会对更新数百万次,效率大大提升。由于样本的噪音和随机性,每次更新并不一定按照减少的方向。
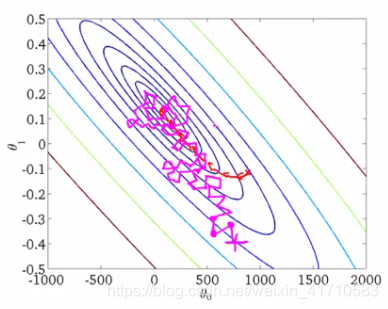
如上图,椭圆表示的是函数值的等高线,椭圆中心是函数的最小值点。红色是BGD的逼近曲线,而紫色是SGD的逼近曲线。我们可以看到BGD(批量梯度下降算法)是一直向着最低点前进的,而SGD明显躁动了许多,但总体上仍然是向最低点逼近的。
最后需要说明的是,SGD不仅仅效率高,而且随机性有时候反而是好事。今天的目标函数是一个『凸函数』,沿着梯度反方向就能找到全局唯一的最小值。然而对于非凸函数来说,存在许多局部最小值。随机性有助于我们逃离某些很糟糕的局部最小值,从而获得一个更好的模型。
代码可以参考上一节
- 动量法(Momentum)
如果把梯度下降法想象成一个小球从山坡到山谷的过程,那么前面几篇文章的小球是这样移动的:从A点开始,计算当前A点的坡度,沿着坡度最大的方向走一段路,停下到B。在B点再看一看周围坡度最大的地方,沿着这个坡度方向走一段路,再停下。确切的来说,这并不像一个球,更像是一个正在下山的盲人,每走一步都要停下来,用拐杖来来探探四周的路,再走一步停下来,周而复始,直到走到山谷。而一个真正的小球要比这聪明多了,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。

在CNN的训练中,我们的开山祖师已经给了我们冲量的建议配置——0.9(刚才的例子全部是0.7),那么0.9的冲量有多大量呢?终于要来点公式了……
我们用G表示每一轮的更新量,g表示当前一步的梯度量(方向*步长),t表示迭代轮数,\gamma表示冲量的衰减程度,那么对于时刻t的梯度更新量有:
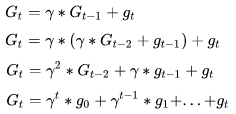
那么我们可以计算下对于梯度g0对从G0到GT的总贡献量为
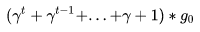
- 对应实现代码
- 结果
前面的一系列文章的优化算法有一个共同的特点,就是对于每一个参数都用相同的学习率进行更新。但是在实际应用中各个参数的重要性肯定是不一样的,所以我们对于不同的参数要动态的采取不同的学习率,让目标函数更快的收敛。
adagrad方法是将每一个参数的每一次迭代的梯度取平方累加再开方,用基础学习率除以这个数,来做学习率的动态更新。这个比较简单,直接上公式。
- 公式

- 介绍

- 代码
- 介绍
https://blog.csdn.net/leadai/article/details/79178787 深度学习最常用的学习算法:Adam优化算法 - 代码
- 结果
为迭代次数以及对应的损失
https://blog.csdn.net/tsyccnh/article/details/76769232 深度学习优化函数详解
https://www.zybuluo.com/hanbingtao/note/448086 零基础入门深度学习(2) - 线性单元和梯度下降

